Chapter 1: State representations
Let’s start with the first big question:
How should I represent my robot?
This turns out to be one of the most important design decisions you’ll make.
The simplest possible robot
The obvious starting point is to treat the robot as a point in space.

This gives us a position in 3D, but these numbers only make sense relative to some coordinate or reference frame.
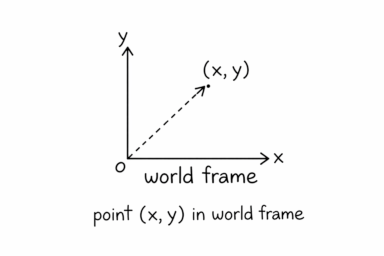
Reference frames
A reference frame is just a coordinate system we use to describe things. The same point can have different coordinates depending on the frame. We usually define:
- a world frame (fixed)
- a robot frame (attached to the robot)
So instead of saying “the robot is at (1, 2, 0)”, we should really say:
“the robot is at (1, 2, 0) in frame 0”
This becomes important very quickly.
Position and Orientation
A point only gives us position, but robots aren’t just points — they have orientation.
Think:
- Which way is the robot facing?
- Where is its camera pointing?
So a robot’s state is really (measured relative to a world frame):
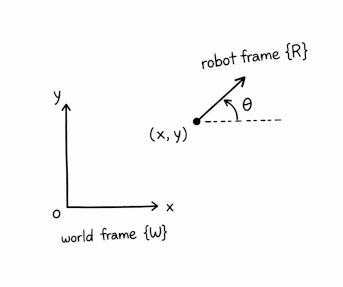
We refer to a robot's position and orientation as its pose.
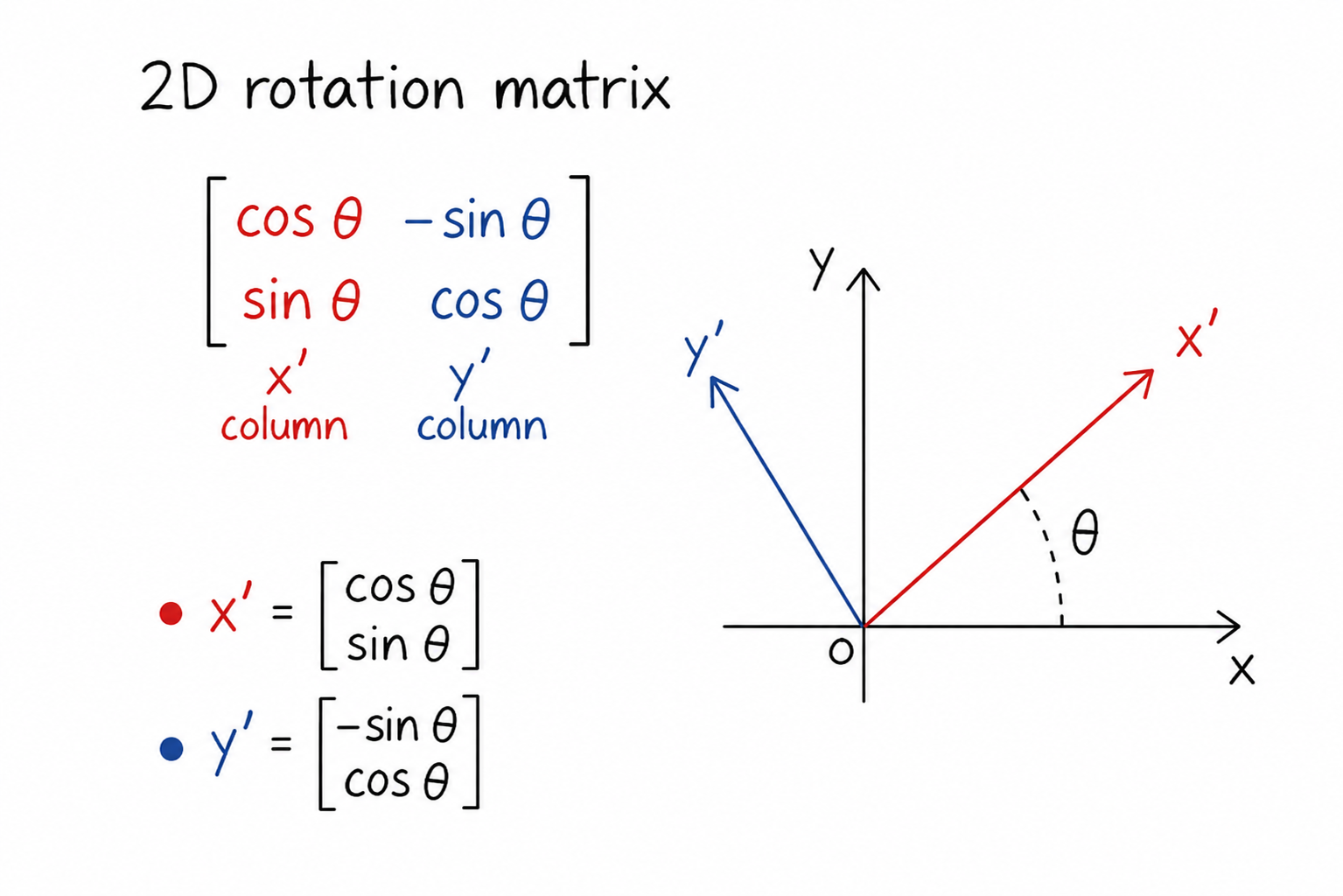
Rotations in 2D
In 2D, orientation can be described by a single angle, . A more powerful way is using a rotation matrix:
This lets us to convert coordinates between frames.
For example:
Means:
- take a point expressed in frame 1
- convert it into frame 0
It also encodes the new coordinate frame directly.
Rotations in 3D
In 3D, things get more interesting. Instead of a single angle, we use a 3×3 rotation matrix:
Each column tells us where the axes of one frame are expressed in another frame. We sometimes build rotations from elementary rotations.
-
Rotation about x-axis:
-
Rotation about y-axis:
-
Rotation about z-axis:
For example:
We can chain these together to describe general 3D rotations, but...
Rotations don’t commute
This can be a problem because rotations don't commute. This means order matters. Rotating around x then z is NOT the same as rotating around z then x.
So we have to be very explicit about:
- the order of operations
- the frame we’re rotating in
Translations
So far we’ve only rotated things. What about moving them? A translation is simple:
Just shift by some vector.
Rigid body motion
When we combine both, we can describe rigid body motion.
This is the fundamental building block of robotics.
Homogeneous transformations
To make life easier, we combine everything into one matrix:
Then we can write:
This allows us to chain transformations easily
We can use this to describe a sequence of poses as a robot moves, or the static pose of a more complex robot, like this PR2 robot (PR2 was a very cool robot released in 2010). We can chain transformations together to build a skeleton or kinematic transform tree (TF) that describes our robot. More on this in chapter 7.
Let’s zoom out a bit though. Everything we’ve done so far is about:
How do I describe where my robot is, and how it’s oriented?
This is useful because we need to describe a robot state to control it, we need to figure out what information our sensors need to extract, but also because when we perceive something about the world, it depends on our frame of reference.
If you get representation wrong → everything else becomes painful.
But describing the robot is only half the problem. We also need to describe the world.
Representing the Environment
Ok, we’ve described the robot. Now… What does the world look like?. Robots have states, but so do environments. How should we represent these.
2D metric maps
The simplest option is to represent the world as a 2D plane and store the exact geometry of the environment at some discrete resolution. For example, the floor plan used by a robot vacuum cleaner.
We can also add various cost maps or layers (traversability, risk, terrain type, wifi strength etc.) to aid navigation.
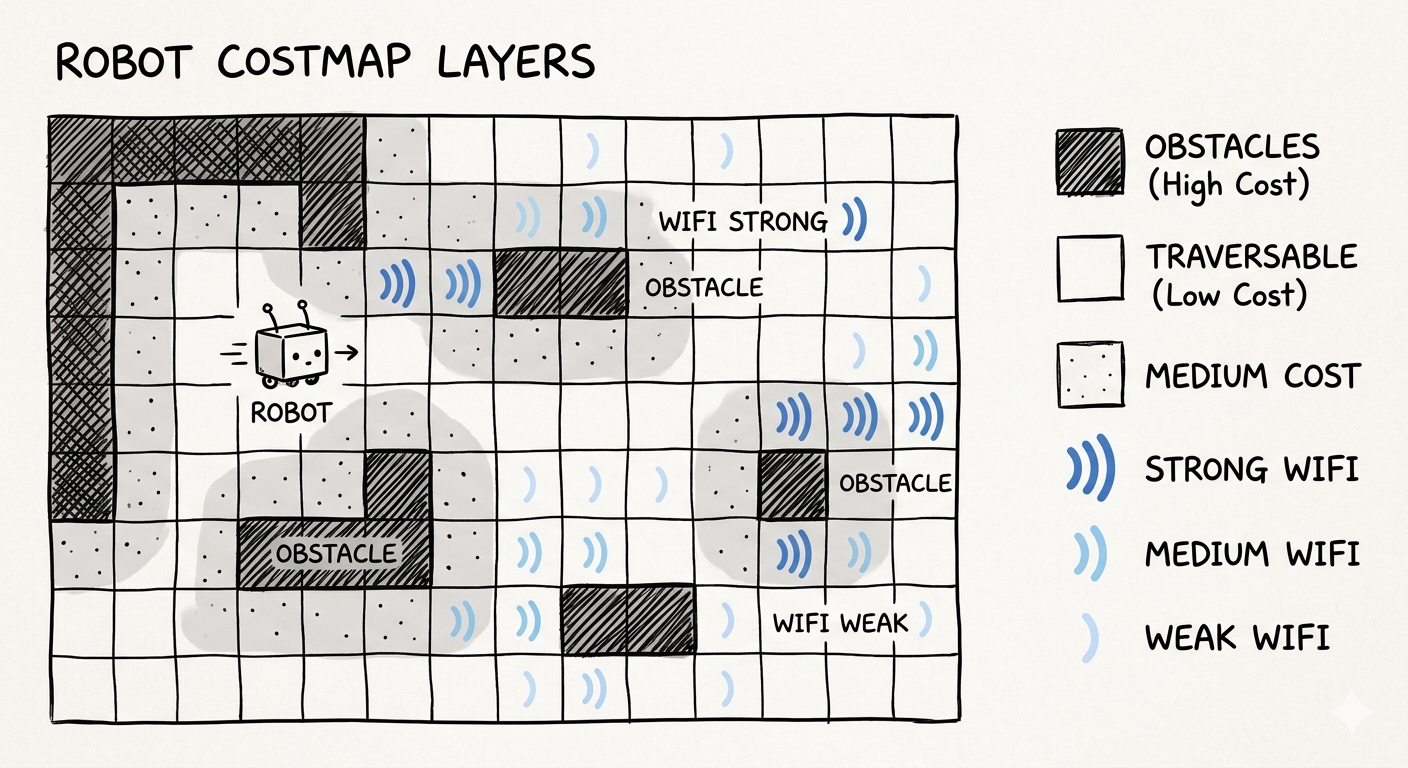
These maps may have limitations, because robots have height, and many environments have more complexity than flattening, eg. a bridge over roads, a table you can or can't drive under. There is a tight coupling between what your robot can sense, how it needs to interact with the world, and your choice of representation. For example, while it makes sense to think about a wheeled robot constrained to a ground plane in 2D, when you add an arm to the robot, this representation starts to make life more painful.
3D metric maps
The immediate answer then is to extend to a 3D map. This could be a point cloud, mesh or volumetric map.
This is more expressive, but requires more compute and more memory. More formally, a point cloud in is a finite set of points with associated attributes:
where for each , we typically store:
- Position:
- Surface normal: (a unit vector; often defined up to sign, i.e. )
- Colour / feature: , typically k = 3 for RGB, but can be any feature dimension depending on the information you want to store.
Defining it mathematically allows us to think in terms of functional operations or processing steps we can perform on this (eg. collision checking, object segmentation and detection). For example, we may transform the pointcloud into a signed distance field that stores the shortest distance between any point in space to the closest edge. This is particularly useful for collision checking.
Occupancy grids
A very common representation that addresses some of these concerns is an occupancy grid. Here, we divide space into cells:
- each cell stores probability of being occupied (or some other state (eg. traversable)). This also handles uncertainty nicely.
So instead of “there is a wall here”, we say “there is a 0.8 probability of a wall here”. We can store these representations somewhat more efficiently using tree-like structures (eg. Octree, kd-trees).
Elfes, A. (1989). "Using occupancy grids for mobile robot perception and navigation." Computer, 22(6), 46–57.
Hornung, A., Wurm, K. M., Bennewitz, M., Stachniss, C., and Burgard, W. (2013). "OctoMap: An efficient probabilistic 3D mapping framework based on octrees." Autonomous Robots, 34(3), 189–206.

This representations are very useful for collision avoidance or planning, but make contact rich tasks more challenging (eg. folding a t-shirt).
Topological maps
Sometimes we don’t care about geometry. I do not store a metric map in my head, and am quite capable of moving around our campus without it. I move to the campus centre by sequencing a set of key goals or waypoints (eg. find my office door, go to lab exit, walk towards the lawn). Why do our robots need a centimeter level representation of their world, which is difficult to scale to large areas.
Instead, maybe it makes more sense to think about graph structures with nodes and edges.
- nodes = places
- edges = connections
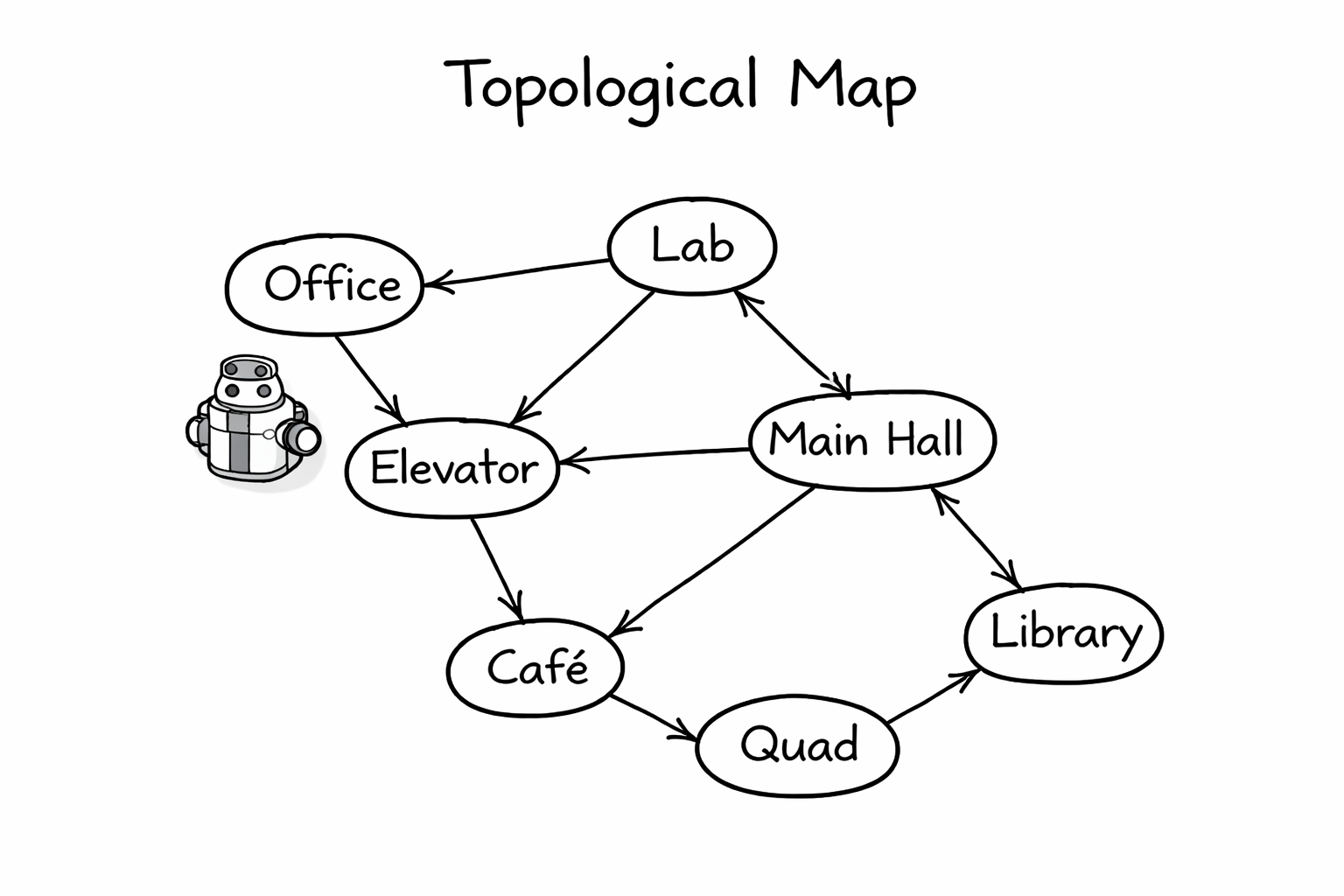
You can imagine breaking a space down into a scene-graph with
- rooms
- corridors
- intersections
- the location of objects or storage
Kuipers, B. (2000). "The Spatial Semantic Hierarchy." Artificial Intelligence, 119(1–2), 191–233.
This is great for high-level planning, but sacrifices some of the information needed for low level control aspects. A common trade-off is to use both, a local map for local planning, and a topological map for global planning.
A major limitation of these map representations is that they are generally static and unchanging. But intelligent robots take actions that change the environment. So we need ways of updating these representations or dynamics or world models, that model how the world changes in response to our robot actions. We will look at this in chapter 3.
Final thought
There is no “best” representation, only the right representation for the task. This is a recurring theme in robotics. The representations above quickly become limited in terms of tasks. In more complex cases, it may be better to learn representations instead. We'll look at this in chapter 9.
Key Papers
Elfes, A. (1989). "Using occupancy grids for mobile robot perception and navigation." Computer, 22(6), 46–57.
Hornung, A., Wurm, K. M., Bennewitz, M., Stachniss, C., and Burgard, W. (2013). "OctoMap: An efficient probabilistic 3D mapping framework based on octrees." Autonomous Robots, 34(3), 189–206.
Kuipers, B. (2000). "The Spatial Semantic Hierarchy." Artificial Intelligence, 119(1–2), 191–233.
Thrun, S., Burgard, W., and Fox, D. (2005). Probabilistic Robotics. MIT Press.
Coming up next
Now that we can represent state…